Designing High-Performance Windows Client/Server Socket Classes
Author: Sahlan Diver, Contractor
Date: Jan 2009
Revised: April 2009
Revised May 2nd 2009 after further
simplifications to the code
Revised May 7th 2009 after further tidying up
the code
Revised October 21st 2010
Contents
Introduction
Theory
IO Completion Ports
Thread Pool Requirement
Completion Port Coding
Simplified Completion Port Coding
Completion Port Problems
Timeouts
Socket close handling and socket object deletion
Graceful socket close
Connected socket closure
notification
Unused Facilities
CancelIo
PostQueuedCompletionStatus
Maximising
Performance
AcceptEx()
Denial Of Service
DisconnectEx()
Threading and Memory Issues
Multithreading Issues
Memory Management
Using an alternative memory cache in C++
Class member function operator new and delete
Zero-byte receive
TCP Packets
WSAOVERLAPPED
Technique for passing data to
completion routines
Alternative to offsetof()
Sockets and Win32 Limitations to be aware
of
C++ socket class design
Testing
Summary
Introduction
While working on a C++ SMTP mail server class,
I came across an article extolling the virtues of Windows I/O Completion Ports
for scaleable, high-performance socket programming. Previously I had not needed to worry about performance in socket
classes, as the applications I had used them in were relatively lightweight.
Clearly the performance requirements of an SMTP server were going to be much
more stringent, so I set about designing some C++ classes to provide socket
functionality using the Win32 IO completion port mechanism.
There were two principal sources of the
information needed to write the code: the MSDN, and the many articles and
source code examples on the very excellent “The Code Project” web site.
Theory
Question:
If this diagram models a single-threaded
application:
![]()
Does this diagram model a multi-threaded
application?
![]()
![]()
![]()
Answer:
It depends. The diagram gives the impression
that the multi-threaded application does three times the amount of work in the
same amount of time, but this would only be true if there were three processors
running simultaneously. In a single processor system, the processor has to
divide its time across the threads, so a more correct diagram would be:

The program is not running any faster, it is
just splitting its available time across its threads.
If threads do not cause a program to run
faster, why bother with them at all? When handling socket send and receives,
for example, why not, in a single-threaded program, do all the i/o for one
socket, then go to the next socket, finally doing the i/o for the third socket?
There are several reasons:
Firstly, a single-threaded model does not scale
to multi-processor machines. A single-threaded program running on a three
processor machine would still only use one processor, whereas a multi-threaded
program could automatically take advantage of the additional processors and run
up to three times as fast.
Secondly, threads are not always fully active.
A thread might need to go dormant while waiting for something to occur, such as
data to arrive from a remote connection. When a thread is put into a dormant
wait state, this will free up processor time for the remaining threads, so the
overall processing time for the tasks is shorter. By contrast, a single
threaded application carrying out tasks one after the other can do nothing but
be idle when it is forced to wait for some external event.
Thirdly, operations carried out by a program
can have timeouts. If an operation in a single threaded application is queued
up behind other operations for too long, it might be aborted with a timeout
error, whereas in a multithreaded application the continual intermittent
activity on an operation keeps it moving along, reducing the possibility of any
intermediate stage of the operation timing out.
It might be thought that, since multi-threading
offers such advantages, all we need to do to design a multithreaded server is
to allow a separate thread to be created to service each incoming client
connection, so that all clients can be serviced simultaneously. Unfortunately
this tactic does not scale well, and the reason why not can be seen if we
redraw our multi-threading diagram to more accurately represent how
multithreading works:
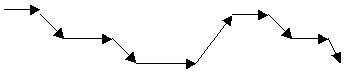
It can be seen that switching between one
thread and another is not instantaneous; some time is lost making the switch,
as represented by the diagonal lines in the diagram This is a fixed amount of
time per switch, so what happens as an application adds more threads is that a
higher and higher proportion of processor time is spent on thread switching and
less and less on actual processing within each thread. Eventually the number of
threads can become high enough that the processor spends all its time switching
from one thread to the next, and no time is spent on actual data processing.
Microsoft provides a solution to this problem,
inbuilt into the Windows O/S. It is known as the IO Completion Port mechanism.
IO Completion Ports
IO Completion ports provide a way that
processor time can be divided between any number of I/O objects, such as
sockets, without requiring a proportionate increase in the number of threads.
Windows
sockets programming is typically done asynchronously, that is, a socket
function is called and returns immediately without waiting for a result. Some
time later when the result is ready, for example a remote connection has sent
some data, the application is notified and the result can then be processed.
IO Completion Ports provide a specialised
notification mechanism for completed asynchronous I/O. Completed I/O is queued
at an object called a completion port which then calls a
programmer-supplied call-back, known as a completion function, to
process the I/O. What is unique about the completion port mechanism is that it
tries to run the call-backs for multiple socket I/O in as few threads as
possible, to maximise efficiency by minimising thread context switching.
The completion function that processes
completed I/O is called within the context of a thread. When the completion
function has returned, the completion port looks to see if it has more I/O
results queued up, waiting to be processed. If so, it immediately calls the
completion function again in the same thread as previously. A whole
sequence of I/O operations can therefore be processed in the one thread,
avoiding losing time through context switching to other threads.
Take an SMTP server as an example application.
The server receives some mail data from a client in a completion routine and,
in accordance with the SMTP protocol sends back a response to the client.
Before further data comes back from that client, I/O might arrive at the
completion port from a second client. The completion port immediately causes this
new data to be processed in the same thread that processed the first client’s
data. No context switch to a second thread is necessary.
The completion port mechanism optimally tries
to use one thread per processor in the system, so if you have a dual processor
machine the completion port can field two I/O completions at a time, through
two parallel running threads, thus automatically doubling performance.
Thread Pool Requirement
Although completion ports will try to use just
one thread per processor, occasionally this ideal is not possible. For example,
the thread in use may have called a blocking function. In such circumstances,
so as not to be delayed, the completion port will grab an additional thread to
use to process other I/O results that are currently queued. So a pool of
available threads is required. The completion port will automatically choose
the most recently used thread, as threads that have not been used for some time
may have had their information swapped out of memory, and would take longer to
reactivate.
Completion Port Coding
Simplified Completion Port Coding
To try to get as reliable a result in as short
as possible a time, I did not set about designing my own thread-pool, but
instead used a Microsoft library function, BindIoCompletionCallback(),
that conveniently allows a socket handle to be associated with a resident
Windows thread pool and completion port:
// binding socket to completion port associated with Windows-managed
thread pool
if ( !BindIoCompletionCallback( RECAST (HANDLE,sockHandle),
SocketCompletionRoutine, 0 ) )
// …
All that was then necessary to do was write the
completion routine for handling completed I/O. This has the prototype:
VOID CALLBACK SocketCompletionRoutine ( DWORD errcode, DWORD bytes_transfered, LPOVERLAPPED overlapped )
Note the pointer to an OVERLAPPED structure. This is a compulsory parameter to asynchronous socket I/O functions which is passed on as a parameter to the SocketCompletionRoutine. We can use the parameter to store additional context-sensitive information that will assist our processing of the call completion.
Microsoft’s OVERLAPPED structure contains very little spare field space for context-sensitive information, so it was necessary to design a new struct which impersonates an OVERLAPPED while at the same time containing additional fields. More of this technique later.
Completion Port
Problems
So
far, the coding of the completion port mechanism sounds very straightforward.
We were able to call a library function that provided us with a
ready-functioning thread-pool and completion port, and we only needed to
provide two pieces of code, the completion routine itself and a special
structure to provide context sensitive data. However there are several thorny
issues involved in completion port programming, which will be discussed in the
following sections.
Timeouts
In
asynchronous design we fire off an operation and forget about it until a result
comes back. What happens if a result never comes back? We need to be able to
set reasonable time-outs on operations and if they haven’t completed within
that time assume that there is a problem and return a timeout error message.
In
my former asynchronous sockets programming, handling timeouts was easy. The
dedicated thread for a connection would simply wait on a handle representing
the completion of the operation. The wait function would have a timeout
specified, so the conclusion of a wait would either be a successful completion
or a timeout error.
Unfortunately
we can’t do this with completion ports because waiting on a result or timeout
will put a completion port thread to sleep until a waited-on condition has
occurred. This will cause the completion port to context-switch to another
thread in the thread pool, as it does not tolerate sitting idle if it has
queued i/o waiting to be processed. If every client i/o operation contained a
wait and forced a context switch, consider what would happen if our thread pool
were of unlimited size, we would be back to the situation where as many threads
were running as there were connected clients, which is not a scaleable
situation. Conversely if we limit the thread pool size, we will then have
queued i/o blocked by i/o, in front of it in the queue, that is waiting for its
threads to wake up. Either way, performance is severely compromised.
Clearly
a different mechanism is needed for handling timeouts, and that mechanism also
needs to be scaleable.
The
solution devised was to have a single extra thread dedicated to monitoring I/O
timeouts.
When
an I/O operation is initiated, it is associated with an enhanced OVERLAPPED
structure. This enhanced structure is made to store the start time of the
operation and the required timeout for the operation. We also store a pointer
to the OVERLAPPED on a special list under the control of the timeout monitoring
thread. The timeout monitoring thread is woken up every second to examine its
list and see if any of the OVERLAPPED’s on it are old enough that their
corresponding I/O operation can be considered to have timed out. If so, the
completion routine is called directly to process the timed-out item and return
an error to the application.
Some
care is needed with arbitrary timeouts. It may be that an i/o operation that we
deemed timed out does eventually successfully return a result to the completion
routine. We can’t then return this result to the application, because we have
already told the application the operation was in error. What we do for a timed-out operation is
leave it’s corresponding OVERLAPPED information on the timeout monitoring
thread’s list. If the operation does subsequently return we will know from the
flag value stored on the list that the I/O was regarded as having timed out, so
we ignore and discard the late returned result. If the operation never returns
there is some slight memory overhead, as the OVERLAPPED structure has to remain
on the list as a precaution and can’t actually be cleaned up until the socket
is closed.
We do know
in a timeout situation the completion routine will be called twice, once from
the timeout thread and once from the i/o thread (either because of a subsequent
successful completion, or because of an i/o abort error when the non-returning
socket is eventually closed) So the first time we report the timeout error, the
second time we do not report but clean up instead. We distinguish the second
time in with the TIMEOUTREPORTED flag. It's not as simple as this, however,
because of thread scheduling. The thread charged with reporting the timeout may
go slower than the one charged with cleaning up the OVERLAPPED. We don't want
any thread to start cleaning up until the other thread has finished with the
data, so what is relevant to cleanup is not which thread enters the timeout
handling code first – that will be given the task of reporting the timeout --
but which thread gets to the cleanup part of the code last -- that will be
given the task of cleaning up.
Socket close handling and socket object deletion
Another problem with io completion ports comes about when wanting to delete a socket object.
Traditionally
in C++, well-designed destructors should clean up the resources used by an
object. This is OK where those resources can be immediately cleaned up, but in
an asynchronous situation, where it might take some for resources to be
released, it can be dangerous to allow a C++ object to be prematurely deleted.
Imagine
this scenario:
1.
We delete a Socket class object
2.
The destructor of the object causes close() on
the socket
3.
Closing a socket causes any outstanding i/o on
the socket to be reported back to the completion routine as having failed with
an error
4.
In the completion routine we try to access the
Socket class object. However the object has already been deleted in step 2, so
we are accessing an invalid object, and the code fails.
This
shows that the socket class designers, rather than the programmers using the
class, need to control precisely when and how a socket object can be deleted.
One
solution in situations like this is to make an object’s destructor wait on an
event handle until a parallel running thread responsible for cleaning up the
object has signalled completion of its task. We can’t do that because we want
to have the option to close a socket within the data processing or error
handlers called by a completion routine, and we have already said above that
any code that waits or blocks a thread during a completion routine is
unacceptable.
A
more sophisticated solution is required. The solution is encapsulated within
the private member functions of our socket classes and also takes advantage of
C++ semantics to ensure safe asynchronous closure and self-deletion of sockets
without any special action being required by the user of the socket classes.
In
summary:
1.
We declare the object’s destructor as “protected”.
This prevents the object from being destroyed by a programmer’s direct call to
delete. The programmer can’t use delete to free up the heap-based object
since the destructor which delete activates is not publicly accessible.
But making the destructor “protected” also implies that we can’t create a local
stack-based socket object, we always have to create it on the heap, since a
stack based object should have a public destructor, callable when it goes out
of scope.
2.
We make use of the fact that closing a socket
causes all pending i/o to be queued on the completion port with an abort error.
This is guaranteed as part of the way in which completion ports work. For each
socket object, we keep a reference count of all pending i/o. When this has been
reduced down to zero through each I/O result being reported back to the
completion port, we know that the socket object is not expecting any further
communications and can now be deleted.
3.
When all pending i/o has returned, the socket
object deletes itself inside the completion routine by doing “delete this;”
This is safe because the protected destructor means that the socket class
object could only have been created on the heap – there is no danger of trying
to delete a stack-based object. However, the protected destructor, although
unavailable to outsiders, is callable by another method of the same class so it
will be callable as the delete in the class method.
4.
Notice that we make the destructor protected
rather than private, so it is accessible to be called in the destruction
of any classes derived from the Socket class.
The above steps give us
controlled, safe self-deletion of a socket object, but there is a vital issue
those steps do not address. How does the application know that a pointer to a
socket object is still valid at any given time? Consider the scenario where a
client socket is connected to a server socket that closes a connection. The
client socket object is then called by the application to send some data.
However the closed connection has caused the socket object to self-delete so it
is no longer valid.
We can only solve this problem by
building in additional constraints. The rule is that a socket object can only
self-destruct after Close() has been called on the object.. C lose() sets a
flag that gives permission to self-destruct once the count of pending i/o has
reached zero. In the example above, we would call Close() on the server side to
close the server socket, this will close the connection to the client. On the
client side, the pending i/o count will also reduce to zero, but the socket
cannot self-destruct because the application has not yet called Close() on it.
Two things can happen, the app may try to use the client object to send more
data in which case it will just get back an “invalid socket” error. Or it may
have finished with the socket and call Close() to clean up the socket. In the
latter case, because the pending i/o count has already been reduced to zero due
to the previously closed connection, the client socket will be able to self-destruct
immediately. So the rule is that to deliberately close and delete a socket
object, Close() must be called. After Close() the socket could self-destruct at
any moment, and no other member functions should be called on it.
An application may have other
reasons to know precisely when a socket has been closed. We therefore provide
the overridable private virtual function OnSocketClosing() for the TCP socket
class. The function is called when a socket is internally closed. This function
is called in the contest of a completion thread so if it changes data used by
the application that data will need to be protected by a critical section.
Note that
ConnectionListeningSockets do not delete themselves on close. They must be deleted in the normal way by calling
delete.
Graceful socket close
Microsoft
say: Shutting down a socket connection involves an exchange of
protocol messages between the two endpoints, hereafter referred to as a
shutdown sequence. Two general classes of shutdown sequences are defined:
graceful and abortive (also called hard). In a graceful shutdown sequence, any
data that has been queued, but not yet transmitted can be sent prior to the
connection being closed. In an abortive shutdown, any unsent data is lost. The
occurrence of a shutdown sequence (graceful or abortive) can also be used to
provide an FD_CLOSE indication to the associated applications signifying that a
shutdown is in progress.
Sockets
need to be closed gracefully, I.e. if there is a data transfer still in
progress, it is allowed to complete
before the socket is closed, firstly so that data is not lost, secondly so that
consequent communications errors do not occur for what should be an error free
operation.
The
WinSock function, shutdown (), is called to close a socket gracefully.
The shutdown action needs to
be different on the server and client sides, because on TCP there is a TCP enforced delay, known as
TIME_WAIT, before a port / i.p.
combination can be reused. The side that does the active close goes to TIME_WAIT.
We don't want the server side
of a socket connection to go into time wait because we want to be able to use
DisconnectEx() to put the socket’s handle into a pool for re-use, to improve
the efficiency at which we can offer new connections.
(See below). These handles need to be reusable immediately..
Calling shutdown(SD_SEND) from the server initiates a
passive close. The client does the final active close by calling
shutdown(SD_BOTH. That way the client ends up in TIME_WAIT, which generally doesn't matter as
much as the server being in TIME_WAIT.
The precise sequence differs
slightly depending on whether the server or client side initiates the close.
Server
side closing:
- if
the server wishes to initiate the close down, it should call shutdown (FD_SEND).
The client receives 0 data bytes telling it that the server is sending no more
data. The client can then call shutdown (FD_BOTH). The server's recv()
completion routine gets any remaining sent client data followed by a zero byte
receive telling it the client has closed down. The server can then close the
connection socket.
Client
side closing:
-
if the client wishes to initiate the close
down, it should call shutdown (FD_SEND). The server receives 0 data bytes in
its completion routine, telling it that the client is sending no more data. It
can then call shutdown (FD_SEND). The client then gets a zero-byte recv
completion and can close, calling shutdown (FD_BOTH) first.
Note
that both sides initially do the same thing, sending FD_SEND. They differ in
how they react to a close down. A virtual function is tested to see whether the
socket class is for the server or client and the final part of the shutdown is
handled accordingly.
Socket Active and Passive Close
To
actively close a socket and close any open connection, call Close()
This
does a shutdown on the actively closed side.
The
passively closed side of the TCP connection then gets a zero byte recv
indicating the connection is closing. When all pending i/o for the socket has
returned with a zero byte recv and the pending i/o count has been reduced to
zero, it does its own shutdown and either closes the socket handle or marks it
for re-use with DisconnectEx.
The
actively closed side goes through the same sequence after a zero byte recv but
has additionally been marked for self-deletion when all pending i/o is zero, so
deletes itself.
A
passively closed socket will not self delete until Close() is called on it.
This is to give the programmer the certainty of knowing that a socket object
ptr is always valid until Close() is called, even if it’s connection has been
asynchronously closed. If it is required that a passively closed socket should
be automatically deleted then OnSocketClosing()
must return true after taking steps to ensure the socket pointer can’t be used
again, e.g. removing it from a list from which it is accessed.
This way there is no danger of a programmer not
knowing whether a socket object pointer is valid or not.
- Actively closed – do not access pointer after calling Close()
- Passively closed – in OnSocketClosing() either mark the pointer for
later calling Close() to trigger self-destruction, and return false. Or
return mark the pointer so it can’t be accessed again and return true to
flag it should self-destruct.
Remember that OnSocketClosing() is called in the
context of a socket object thread, application objects it accesses like lists,
should be protected by their own critical section.
Redundant socket closure notification
When a socket connection is closed by the ‘other
side’ of a connection we need to know about it, so we can close the socket
object corresponding to the connection, inform the user that the connection is
closed, and clean up.
Formerly we registered for the FD_CLOSE event and
monitored for this in a separate thread dedicated to detecting the close of the
connection. This solution had two problems
1.
It
required creating an extra thread per connection. Although the thread was
dormant, waiting on an event, this would nevertheless create overhead that
might limit scalability.
2. In testing we found
that the FD_CLOSE could not be relied on, and was sometimes leaving connections
hanging without proper termination.
Fortunately we notice that all closed connections infallibly return zero
bytes with no error as their closing recv() operation, and we now rely on this
to start of the socket close sequence described above. This simplified the
design by removing a thread and also by removing a redundant mechanism – if a
zero-byte receive is sufficient to detect socket closure then we don’t need to
handle FD_CLOSE as well.
Unused Facilities
CancelIo
CancelIo() was considered as a way of
cancelling i/o operations on a socket without having to close the socket. The
socket could then be immediately re-useable. Unfortunately there is a problem.
Before Windows Vista, there is no way of canceling the i/o on a socket unless
the thread issuing the cancel request is the identical thread to that which
issued the i/o request we are trying to cancel. If we were managing our own thread pool this would be difficult
enough to achieve, but we chose to initialise our sockets by calling BindIoCompletionPort()
which means that we are using an internal Windows thread pool over which we
have no control. Because of this limitation of CancelIo() we decided not
to give it any further consideration.
PostQueuedCompletionStatus
This function can be used by a programmer to
post an item to a completion port. There are a couple of
cases where in our own threads we need to
post an item to a completion port. However,
because we used BindIoCompletionPort(), we don’t have the actual handle of the completion port, so we can’t
call PostQueuedCompletionStatus().. Instead the code calls the
completion routine directly, bypassing the completion port. The completion
routine will be called within one of
our socket class worker threads and not within a thread from the Windows
thread pool. However, the code is designed for thread safety so that calling
the completion routine in any thread is not a problem.
Maximising performance
Various articles to be found on the Internet suggest
ways in which socket code can be designed to enhance performance. There is no
harm in following these hints, particuarly where they are easy to code.
AcceptEx()
Several articles on server design recommended
using AcceptEx() for the sockets that a server creates to seviceclient
connections. Creating a socket and opening it for connection is apparently an
expensive operation in terms of time. AcceptEx() allows sockets to be
created and opened in advance of a connection being made. The recommendation is
to keep a pool of these sockets available to speed connection times. This
recommendation was followed.
A further advantage of AcceptEx() is
that it can combine both connection and the receiving of the first data from
the client into a single operation, thus further increasing efficiency. The
read data is queued to the completion port, just like a regular read.
The code uses WSAEventSelect to request the setting of the FD_ACCEPT event
when a connection is ready to be made but there are no more pre-opened sockets
left in the pool. A
special thread waiting on this event can create a new stock of required sockets
and call AcceptEx on them.
Denial Of Service
A malicious client can make a connection but
then not send any data. In a denial of service attack a multitude of such
inactive connections are requested, leading to the pool of sockets being used
up and more needing to be created. Eventually one hits a resource limit of too
many created sockets.
So when asked to create more
sockets by an FD_ACCEPT event, get_socketopt() with the SO_CONNECT_TIME
option is used to test connection time. Any sockets connected for a long time
without sent data are closed and deleted.
DisconnectEx()
Several articles recommended using DisconnectEx()
to disconnect sockets when finished with but keep them available for reuse.
Reusing an existing socket offers performance benefits over discarding a socket
and having to create a new one when required.
A limitation is that a disconnected socket can
only be immediately re-used if not subject to the TCP time wait after closure.
This limitation is placed on a socket on the disconnecting side. Our code, as
described above in this document, ensures that the side performing shutdown is
not the server rather but the client, so that DisconnectEx can always be
applied to sockets on the server side.
When a socket is disconnected, it is placed on
a separate list for re-use. When we next get an FD_ACCEPT, showing that we have
run out of sockets in our pool, we first grab all the sockets on the
disconnected list and try to reactivate them with AcceptEx(). For simplicity,
any such sockets that give an error on reactivation are simply discarded.
Following the reactivation of former
disconnected sockets, we look at the new size of the socket pool, and if
smaller than a specified minimum size, we create more sockets and pre-accept
them with AcceptEx, until the pool is full.
When a new socket is required we remove it from
the pool.
We found an unexpected problem with
DisconnectEx. At each FD_ACCPET we first call AcceptEx() on formerly
disconnected sockets, then we do a check for denial of service, by checking how
long the socket has already been connected. What we found was that the
getsockopt() routine for returning connection time returned the time since when
the socket had first been connected, before it was disconnected for
re-use. Therefore the denial of service test was rejecting the socket by
looking too far back into its connection history.
We worked round this problem by testing the
connection time immediately after calling AcceptEx() on a formerly
disconnected socket, so this gives us the time of reconnection. Any future DOS
test is made to refer correctly to this latest reconnection time, which we
store in the socket object.
Threading and
Memory Issues
Multithreading Issues
The code makes use of threads it creates itself
to monitor timeouts, acceptance of incoming connections and closure of
connections. There is the possibility of simultaneous access of the same data
between these threads and the completion port threads. All such data is
protected by CRITICAL_SECTION objects. Critical sections are the most efficient
method in Windows of protecting data from simultaneous thread access.
We know that completion ports try to keep the
number of threads in use to a minimum. This gives an additional advantage in
the matter of access to shared data. The likelihood of a thread having to wait
temporarily while another thread accesses critical section protected data is
greatly reduced because there are relatively very few threads running.
Memory Management
Sockets
communication inevitably involves memory buffers, and some articles on sockets
programming suggest caching freed-up buffers for re-use, to reduce the time
spent on allocating memory. Other articles caution against this by saying that
one would want to be certain that we really were designing a caching mechanism
more efficient than the default heap.
Having
made several attempts in the past to design a fast memory cache, I considered
it worthwhile re-visiting the subject.
I was not very happy with my past designs which involved too much
searching in the cache for a memory block of the correct size. I tried to make
the search algorithms efficient but I had little evidence they bettered the
default heap mechanisms. So I considered the problem afresh.
It
seemed to me that the ideal cache mechanism allows one to retrieve a block of
memory of a given size in just one step, without any kind of looping search.
Suppose
there were an array of pointers to stacks of free memory blocks.
o
Array slot number 10 would point to a stack of
memory blocks of size 10 bytes
o
Slot number 11 would point to a stack of memory
blocks of size 11 bytes
o
Slot number 12 would point to a stack of memory
blocks of size 12 bytes
o
and so on.
Then
if you wanted say 12 bytes, one step would take you to straight to the stack of
12-byte blocks and you could just grab the top block off the stack. Or you
could get new memory from the default heap if the stack were found to be empty.
Likewise putting the 12 byte block back when finished with would only require
one step to find the stack where the block should go.
The disadvantage of this proposal is the enormous amount of memory that would be taken up by the array and the stacks because of having a separate stack for every possible size of memory block.
Suppose, however, we increased the block size increments, so we had something like this:
o
Slot number 10 would point to a stack of memory
blocks of size 1000 bytes
o
Slot number 11 would point to a stack of memory
blocks of size 1100 bytes
o
Slot number 12 would point to a stack of memory
blocks of size 1200 bytes
If
we wanted some memory, we would round up the nearest size. For example, if we
wanted 932 bytes we would take a 1000 byte sized block and just ignore the
surplus trailing 68 bytes of the block. This approach keeps the cache size much
smaller, at the expense of wasting a bit of memory in the application. The method
also has the compensating advantage that the chance of resuing any block is
greatly increased. For example, a cached 1000 byte block could be used by any
memory request for between 901 and 1000 bytes of memory. There’s less likely to
be infrequently used sizes of memory block sitting on the cache doing nothing.
Instrumenting solutions like this is vital. When a cache designed according to the ideas above was first instrumented with a test program, it was actually found to be slower than the default heap! This was quickly traced to a mixture of genuine bugs and silly mistakes. However, after putting these right, the cache performance was still found to be unpredictable. Eventually the cause was discovered -- the caching code was fine, but there was a fault in the design of the code for reorganising the cache when too much memory had been placed on it. After revamping the algorithms, a test rig program showed performance increases, in release builds, of between 20 – 70 times the allocation/deallocation speed of the default heap. So this proved to be an experiment worth undertaking
Using an alternative memory cache in C++
The reader will know that memory allocation for
an object and calling of the constructor for an object is achieved through a
single operator; new.
For example:
std::string s = new
std::string ( “Hello” ) ;
// 1) new gets memory from
the heap
// 2) new calls the
constructor for the string, passing it “Hello”
It is possible to redefine new to
use alternative sources of memory. We don’t want this, however. We want our
applications to continue to use the default heap, but for a limited number of
socket buffer allocations we wish instead to use our fast memory cache
described above. It’s no problem to design a class or function that will return
us a pointer to some allocated memory.
e.g.
class FastHeap {
public:
void * Allocate (size_t) ;
void DeAllocate ( void * ) ;
}
;
but how do we construct a C++
object using this memory, as new() insists on using the default heap?
Fortunately C++ provides a way to
get what we want. I mention this here because the techniques are not used very
often and the reader may not have come across them before.
There is a special operator
function called the “placement new” which performs the dual function of “placing”
an object at a memory address specified by the programmer and then calling the
object’s constructor.
For our string example, the syntax
looks like this:
FastHeap fastHeap ;
void * mem =
fastHeap.Allocate(sizeof(std::string)) ; // get memory
std::string * s = new ( mem ) std::string ( “Hello” ) ;
// place and construct object
The converse problem occurs when
we want to delete the object. The standard operator delete calls the objects
destructor, then deallocates its memory onto the default heap. We don’t want
the second part of the operation.
Again C++ provides a
way to get what we want. We can call the object’s destructor directly with some
special syntax. Then we can deallocate our memory back to our fast heap.
s->std::string::~std::string()
; // call destructor
fastHeap.Deallocate ( &s
); // fee up memory
A lot of the time we use FastHeap to
allocate simple byte buffers for socket data, but we also happen to use the FastHeap
to allocate C++ class objects having constructors and destructors and the above
techniques are used for that.
Class member function operator new and delete
An alternative technique for
allocating and deallocating through an alternative heap, is to define member
operator new and operator delete functions for a class. Any call to new and delete uses these
functions for the to get and free the memory, so the functions can be defined
to use alternative heaps. The advantage is that there is no need for a
placement new, or an explicit constructor call since the normal construction
and destruction mechanisms are applied by the compiler -- all that is different
is the source of the allocated memory. We use this latter technique in the
code.
Note that operator new and operator
delete are static functions since they have to be called when an object is
either not in existence yet or is in the process of being destroyed. They are
static implicitly and do not require to be declared as static.
Zero-byte receive
The alternative memory cache described
above gives us fast reallocation of memory. However there is another problem
associated with memory. At every send or receive operation, the data buffer
submitted will be locked. When memory is locked, it cannot be paged out of
physical memory. The operating system imposes a limit on the amount of memory
that can be locked. When this limit is reached, which it will if there are a
very large number of connections, the overlapped WSARecv() operations will fail
with the WSAENOBUFS error.
This problem is solved by a technique known as “zero-byte receive”. We call WSARecv() to ready our socket for the next data receive, but we specify a zero-byte buffer. Because the buffer used is zero length, no memory is locked by OS. Thus a server
can accept more client connections and
can handle more IO before it reaches its locked memory limit.
When data is received for a particular
client, we do:
·
Set the
socket non-blocking
·
Read the
data in a non-overlapped loop until WSARecv() returns WSAEWOULDBLOCK., showing that no more data is available
This design will thus maximise the
possible concurrent connections by minimising the amount of memory that is
locked at any one time.
The downside of this approach is the
receive loop. Any excessive looping for large amounts of data in a recv would
mean that data throughput is sacrificed on each connection.
We add an algorithm we devised to
optimise the looping as follows:
·
Start with
a previously determined buffer size (See below)
·
Receive
data up to the buffer size
·
If we
receive the exact size, the buffer size may not be big enough, as there may be
more data to receive, so we double it in size and then carry on getting the
rest of the data, doubling in size each time we run out of space.
·
We carry on
looping recvs until they return with WSAEWOULDBLOCK, signifying there is no
more data
·
We save any
increased buffer size to reuse as the start size next time, so that the socket
is always optimised for receiving data of the same or less the amount received
in any block so far.
Of course, this optimisation will be less than
effective if most data is received in only small chunks with just an occasional
large chunk, because then we will be getting a larger amount of memory than we
need for most receives. For this reason, it should be possible for the user to
fine-tune the optimisation by specifying a start size and an upper limit for
the buffer size. We have not added this facility yet.
TCP Packets
The TCP
socket class contains virtual functions for identifying and handling TCP
packets. The classes ProcessRecv() has been overridden to call a virtual
function ExtractPackets() which should be defined by a derived class to analyse
the data into packets, returning only whole packets and keeping back a trailing
partial packet until the conclusion of that packet is received in the
subsequent ProcessRecv(s). The extracted packets are passed on to
ProcessPackets(), which a derived class must define to act on appropriately.
If it is
not required for the derived class to process packets, then ProcessRecv()
should be overridden instead to process the raw received data in some other
way.
WSAOVERLAPPED
Technique
for passing data to completion routines
Microsoft
defines an WSAOVERLAPPED structure that must be supplied to i/o function calls
for the purpose of passing data that may be needed by completion routines.
Since the data is passed as a pointer we can supply a pointer that actually
points to a much larger structure containing context-sensitive data of our own
that we need in the completion routine.
An
example of such a structure is:
struct
OVERLAPPEDPLUS {
OVERLAPPEDPLUS ( WinSocket * originator,
DWORD timeout_secs ) ;
~OVERLAPPEDPLUS () ;
// …………..
enum
CompletionState { PENDING, TIMEDOUT, TIMEOUTREPORTED, COMPLETED }
WSAOVERLAPPED
wsaOverlapped ; // used by Winsock
WinSocket * winSocket ; // the socket
that initiated the overlapped operation
DWORD timeoutPeriod ; // 0 for infinite
timeout, or timeout in seconds
DWORD queuedTime ; // for the timeout
monitoring thread
CompletionState completionState ;
int timeoutHandlersCompleted ;
} .
There is a derived class hierarchy of
these structs, namely UDP_OVERLPAPPED, TCP_OVERLAPPED, ACCEPT_OVERLAPPED, all
derived from the base OVERLAPPEDPLUS and serving UDP,
TCP and connection completion operations.
It should be noted that connection completion does not occur in the
connection listening socket but in the sockets created by it to service the
connection.
The question is how can we pass a pointer to our enhanced structure to a Microsoft routine that is expecting a pointer to an entirely different structure? It may be that the WSAOVERLAPPED field, being the first declared in the struct, is at offset zero, but it is not safe to rely on that assumption. We need to do this in a portable way that makes no assumptions about how the fields will be offset within the structure.
The
answer should be that we use a little known C and C++ macro, offsetof(),
to get the offset of the WSAOVERLAPPED field within the OVERLAPPEDPLUS structure. By adding or
subtracting the offset we can convert the address of one structure to the
corresponding address of the other.
Alternative to offsetof()
Unfortunately OVERLAPPEDPLUS
and its derived classes break the rules for offsetof() in that they
contains member functions are not just a simple data objects.
I found a neat solution in a
programmer’s blog. Unfortunately I have lost his name or I would credit him
here. He said that the rule is enforced because offsetof() works by
pretend placement of data at address zero and then working out the address of
the required field relative to the zero address placement of its containing
object. The compiler doesn’t like object member functions used on an object
placed at the invalid address of zero, so it issues an error. The work round is to devise our own version
of offsetof(), which places the object at non-zero address, 0x0000001,
and works out the offset of the required field from that non-zero address by
subtracting 1 from the field’s address:
#define fieldoffset(classname,fieldname) ((size_t)&(((classname*)1)->fieldname)-1)
Sockets and Win32 Limitations to be aware of
1) WaitForEvent routines cannot wait on more than 64
events in a single thread.
This is not a problem for our code as our waits are
waiting on three events at most.
2) It is a very bad idea to bind a client to a
specific port
This one caused us huge grief in our first test
program. We bound the client to a specific port when connecting to the server,
and were able to open and close the socket without a problem. But then we
couldn’t reconnect on the same port. Much time was spent looking for a software
bug that didn’t exist. Here’s the real reason for the problem: (quote) “When you close a TCP
connection, it goes into the TIME_WAIT state for a short period
(between 30 and 120 seconds, typically), during which you cannot reuse that
connection's "5-tuple:" the combination of {local host, local port,
remote host, remote port, transport protocol}. (This timeout period is a
feature of all correctly-written TCP/IP stacks, and is covered in RFC 793 and
especially RFC
1122.) In practical terms, this means that if you bind to a specific
port all the time, you cannot connect to the same host using the same remote
port until the TIME_WAIT period expires”
C++ socket class design
A common mistake seen in the design of C++
class hierarchies is to stuff the base class of the hierarchy full of too much
functionality. We know for sockets that we might need udp sockets, tcp sockets,
bound and unbound sockets, sockets that read and write data, sockets that
accept connections from other sockets, sockets that are simple clients
connecting to servers, and so on. It could be tempting to put all that
functionality in the base class -- after all, base classes are supposed to
provide code to assist their derived classes. Then in the base class member
functions we just test the type of the derived class and make decisions
accordingly: if the derived class is for a udp socket, do this, if it is for a
tcp socket, do that, and so on.
This way of designing class hierarchies in C++
is bad for at least the following reasons.
1)
It breaks encapsulation. A base class should not
hold any knowledge of matters that are the responsibility of a derived class.
It should be as separate from its derived classes as it would be from classes
not related to it by inheritance. If you are going to have classes all knowing
about each other’s internal workings then you might as well not use C++ at all
2)
It effectively creates one giant base class
that knows everything there is to be known about the problem domain, with the
derived classes having only trivial functionality. Such code is difficult to
maintain because it is usually far too voluminous and muddled; the opportunity
for clarity and separation has been lost.
3)
You can’t derive new classes without adding to
the code in the base class that accommodates the existing special cases.
Alteration of existing code increases the likelihood of disrupting existing
code and extending the testing cycle unnecessarily.
By contrast our design splits the socket
functionality into a hierarchy of classes that each add progressive
functionality to their immediate base class.
Use of Bridge Pattern
An annoying problem when including Microsoft
headers in class library headers is that they are order-sensitive and often
clash with other Microsoft headers included in an application along with the
library headers. The Microsoft sockets headers are amongst those that seem to
give this problem. A good solution is
to use a bridge pattern design where the public requestor class used by an
application forwards its calls to an implementor class that does the real work.
Only the implementor class code need include the Microsoft sockets headers, so
there is only the implementor source file in which to solve any header clashes,
and the application gets no nasty surprises.
Another advantage of the Bridge pattern for our
sockets classes is that we can hide away a large volume of implementation
detail in the hidden implementor classes thus simplifying the header used by an
application. It leaves a public interface to the I/O completion port
functionality is that very simple and straightforward.
Testing
Two GUI-based test programs were written.
A server test program creates a server at a
known address and port, and can receive incoming connections and data. Any
received data it echoes back to the sender.
A client test program creates 1 .. n clients at
an ip and ports chosen by itself and fires off messages at a selectable time
interval to the server’s known i.p. address and port.
The server reports progress at one second
intervals, the client reports progress more frequently.
The server was run on Windows 64-bit XP
Professional on a dual-processor PC. Two clients were run simultaneously, both
on 32-bit machines, one running XP Home, the other running Vista Home. The
relevant test port was opened on the Windows firewall.
- Running server and client on the same pc, it was noticed that
performance on the client pc’s could not go much above 4000 messages per
second, regardless of the connections. We have not had time to meter the
code yet, but wonder if this is a limitation of non-server editions of
Windows. .
- Running server and client on the different pc’s we were not able
with many sockets to send more than 10 messages per second, and assume
this to be a limitation of our network, router and firewall combination.
- The ‘server’ machine was capable of receiving the data sent by both
client pc’s simultaneously, working at their maximum rate.
The UDP sockets have not been tested.
The Recv and Send timeout facility was tested
briefly early on in the development.
We noticed a small memory leak on the server
side in testing. We have overridden new and delete operators that can test for
memory leaks but have not had time to run these tests yet.
Sockets programming is very time and sequence
sensitive. Multi-threading, the use of threads with overlapping
responsibilities, the use of a Microsoft thread pool to which we have no direct
access and the high-speed and high-volume nature of the data flow can make
certain problems impossible to trap in the Visual Studio debugger. For these we
used a simple trace function writing to a text file to get the precise sequence
of events. The trace function used a critical section to protect against
simultaneous multi-threaded access. The actual traces have been removed from
the code, though the trace function remains.
Summary
This document started by describing the need
for a more efficient set of socket classes that would be fully scaleble to the
stringent requirements of an SMTP server.
The document moved on to a discussion of the
theory behind IO Completion ports followed by some notes on how these ports can
be used very easily by calling just a handful of Win32 library functions.
The document then discussed issues such as
handling timeouts and asynchronous socket closure that make IO completion port
programming much less simple than it might appear to be at first sight.
The document concluded by setting out the need
to simplify and clarify C++ class design by clearly separating out specialised
functionalities into derived classes and resisting the temptation to
incorrectly cram all functionality into a single base class.
The described socket classes provide a
lightweight and straightforward interface to Windows IO completion port
functionality, with all technicalities relating to io completion ports hidden
away in the private implementation of the classes. Someone who knew almost
nothing about I/O completion ports could use these classes with confidence. The
only rule they need to be aware of is to try to avoid making thread-blocking
calls (such as WaitForSingleObject() during their handler functions for
received data and errors, as blocking calls adversely affect the efficiency of
io completion port threads.